Architecture
Ingestion pipeline
Section titled “Ingestion pipeline”The ingestion pipeline is responsible for taking a video input from the client and turning it into a set of searchable embeddings stored alongside metadata in the database. It does this through an event-driven architecture that decouples video upload, embedding generation, and database persistence.
Video Upload
Section titled “Video Upload”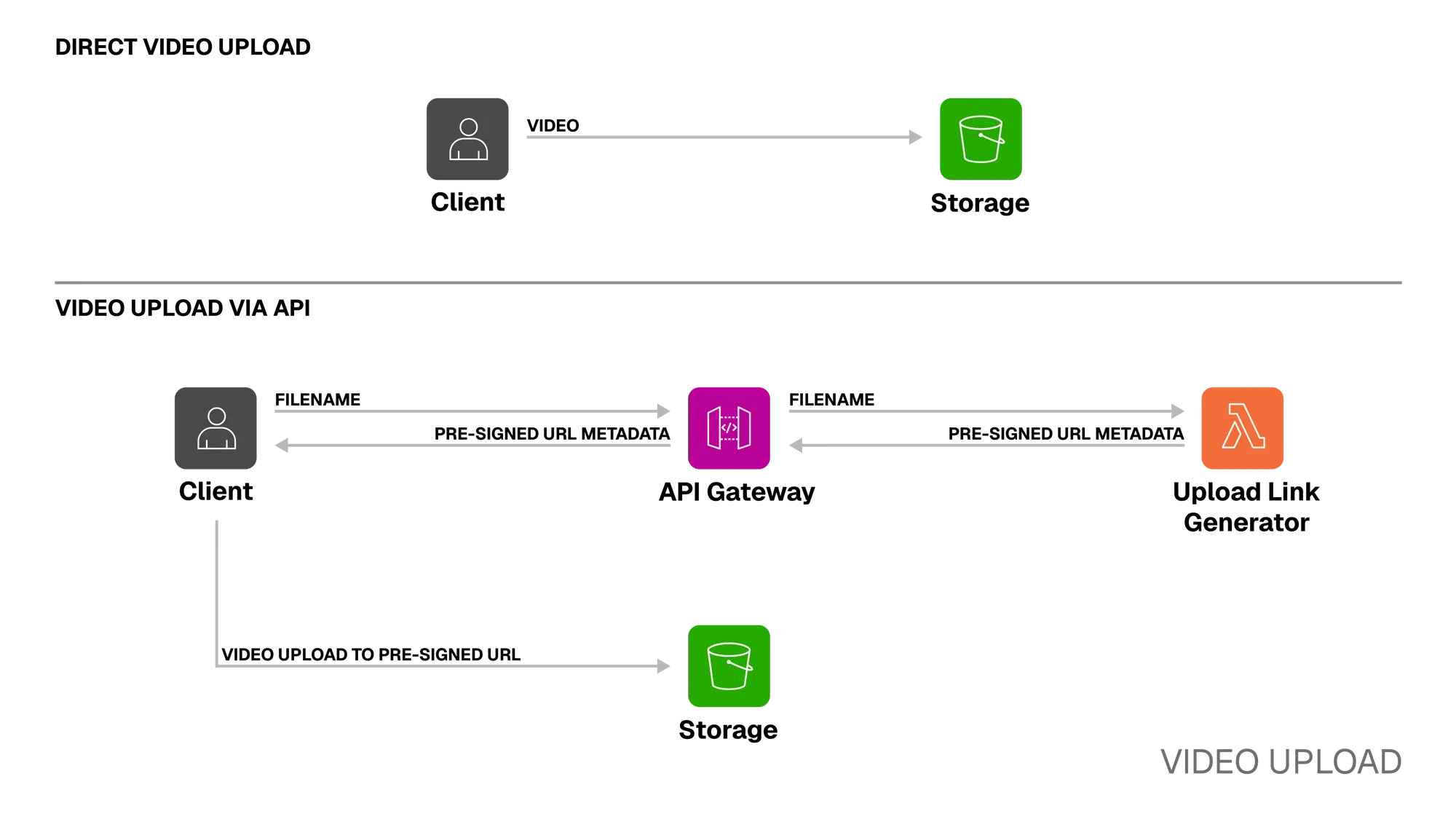
Step 1. Client → Storage
The ingestion process begins when the client uploads a video to a private Amazon S3 bucket. This can be done through two main paths:
-
Direct to S3: Videos can also be uploaded directly to the S3 bucket using the AWS Console or other S3 compatible integrations. External access to items in the bucket is always managed by generating temporary presigned URLs.
-
Via the API: The Kubrick API provides an endpoint that returns a temporary presigned URL for uploads. When the endpoint is called, the Upload Link Generator Lambda generates a presigned URL, which gives the client temporary permission to upload to the private S3 bucket. This approach also allows us to support uploading videos larger than the AWS API Gateway’s 10 MB payload limit.
Embedding Generation
Section titled “Embedding Generation”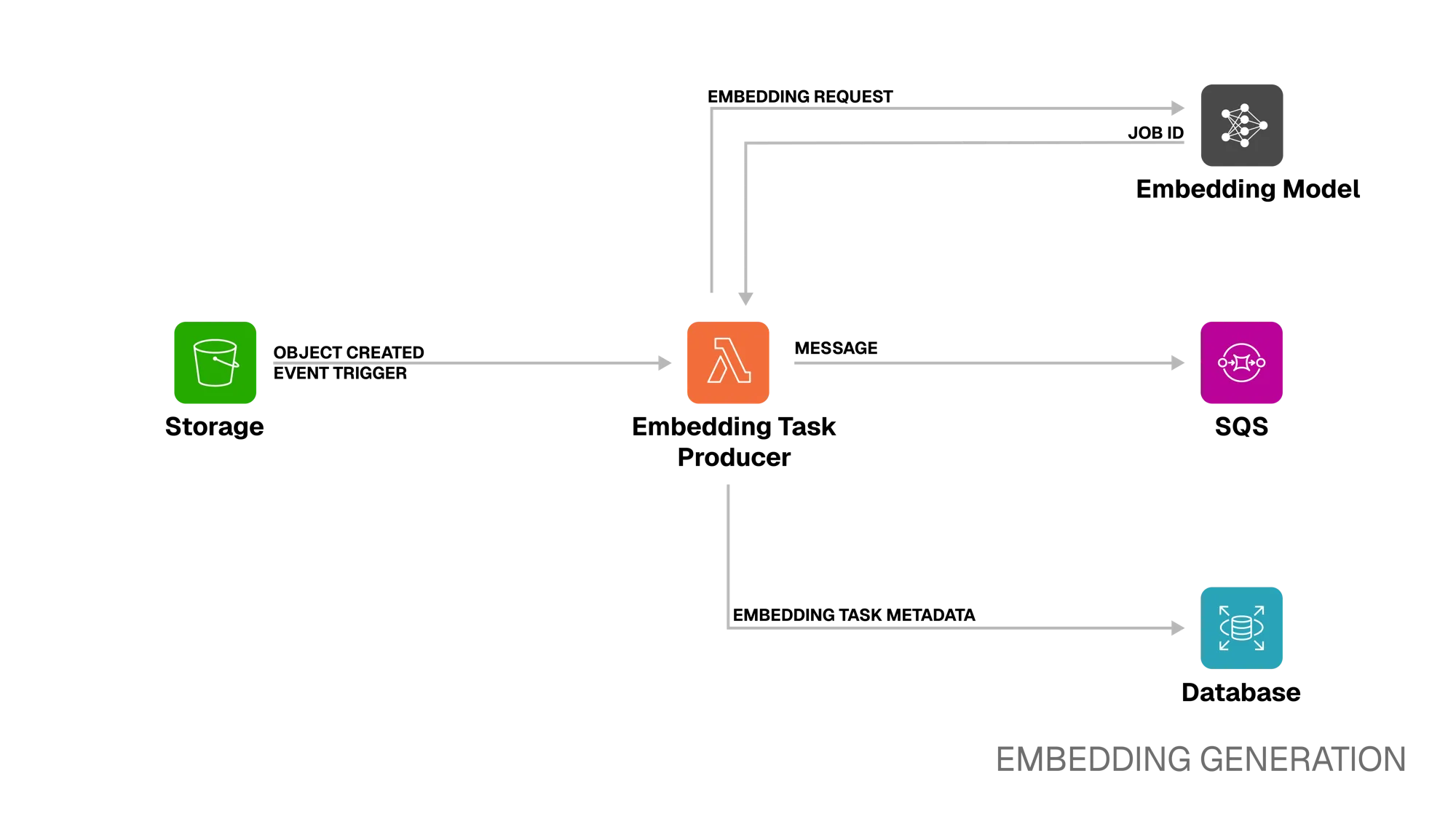
Step 2. Storage → Embedding Task Producer
Once the video is in S3, the bucket emits an event that triggers the Embedding Task Producer Lambda.
Step 3. Embedding Task Producer ⭤ Embedding Model
The Producer Lambda performs initial validation to ensure the object is a valid video. It then generates a presigned URL to give the embedding model temporary access to the video file.
The Lambda then sends this URL in an embedding request to the embedding model’s API. The embedding model creates a job for that embedding request and respond with a job ID.
Step 4. Embedding Task Producer → SQS
Next, the Lambda publishes a message to an SQS queue. This message contains the job ID, which will be used to query the status of the embedding job as well as for retrieving the embedding when it is ready.
Step 5. Embedding Task Producer → Database
The Lambda also records a new “embedding task” in the database with the status
processing. Since generating an embedding is an asynchronous process handled
by an external service, Kubrick tracks the status of each job in the database
until completion or failure - allowing the client to monitor the progress of
their embeddings.
Structured error handling ensures that any ingestion failures are logged both in
application logs and in the tasks database table.
Database Persistence
Section titled “Database Persistence”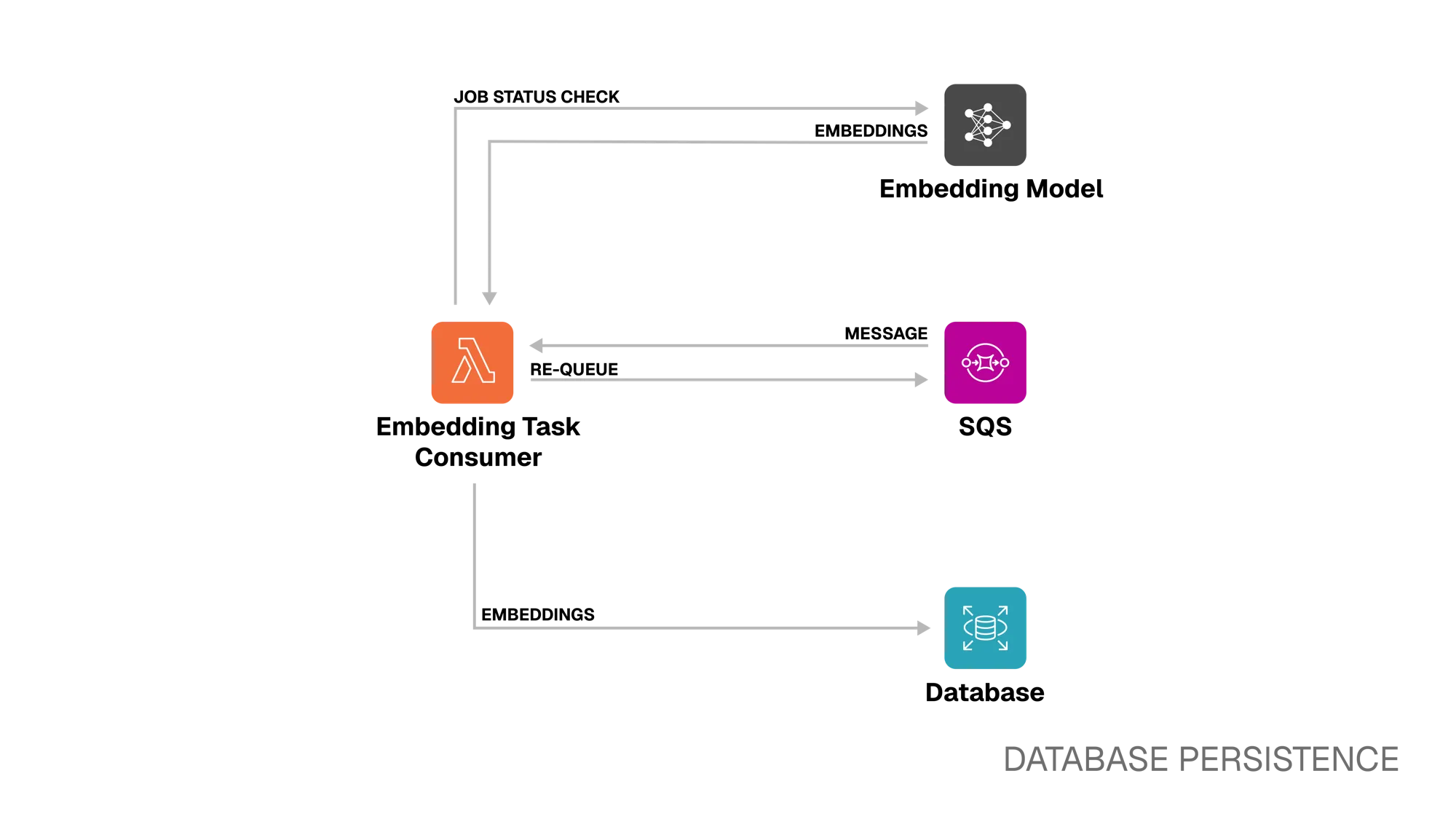
Step 6. SQS ⭤ Embedding Task Consumer
When a message is placed in the queue, SQS triggers the Embedding Task Consumer Lambda, which begins polling the embedding model for the job’s status. If the job is still processing, the message will be re-queued with a short visibility timeout so the Consumer Lambda can check again later.
Step 7. Embedding Task Consumer ⭤ Embedding Model
The Lambda checks the job status:
- If the status is Processing, the message is re-queued as described above.
- If the status is Failed, the database embedding task record is updated to
failed. - If the status is Ready, the embeddings and metadata are retrieved from the model.
Step 8. Embedding Task Consumer → Database
When embeddings are ready, the Lambda stores them alongside the video’s metadata
in the database. The embedding task record is then updated to completed,
making the video immediately available for semantic search queries.
Search and Retrieval
Section titled “Search and Retrieval”The search and retrieval pipeline is responsible for taking a user’s query, whether text, image, audio, or video, and retrieving a set of relevant video segments. The following steps describe this process in detail.
Processing the Query
Section titled “Processing the Query”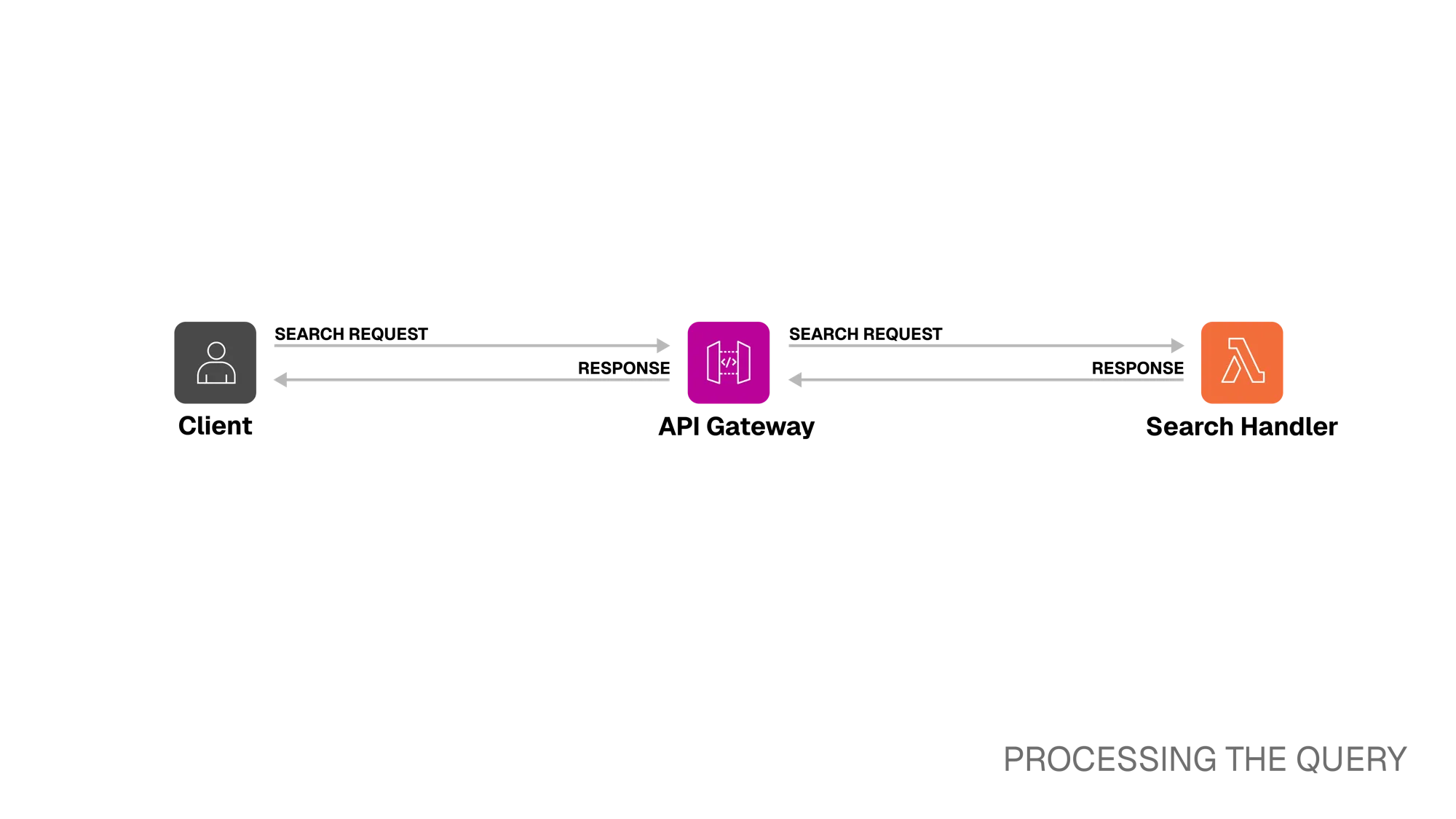
Step 1. Client ⭤ API Gateway
The Kubrick Search API supports multiple query types:
| Query Type | Input Method | Limitations |
|---|---|---|
| Text | String | 77 tokens 1 |
| Image | File upload or URL | Upload ≤ 6 MB |
| Video | File upload or URL | Upload ≤ 6 MB |
| Audio | File upload | Upload ≤ 6 MB |
If files are uploaded directly, they are processed in-memory by the Search Handler Lambda, avoiding temporary S3 storage. Larger files can be sent via URL.
Read more about the /search endpoint in our
API documentation
Step 2. API Gateway ⭤ Search Handler Lambda
Once the request reaches the Search Handler Lambda, it is validated and parsed into an object containing query type, filters, and similarity thresholds
Retrieving Results
Section titled “Retrieving Results”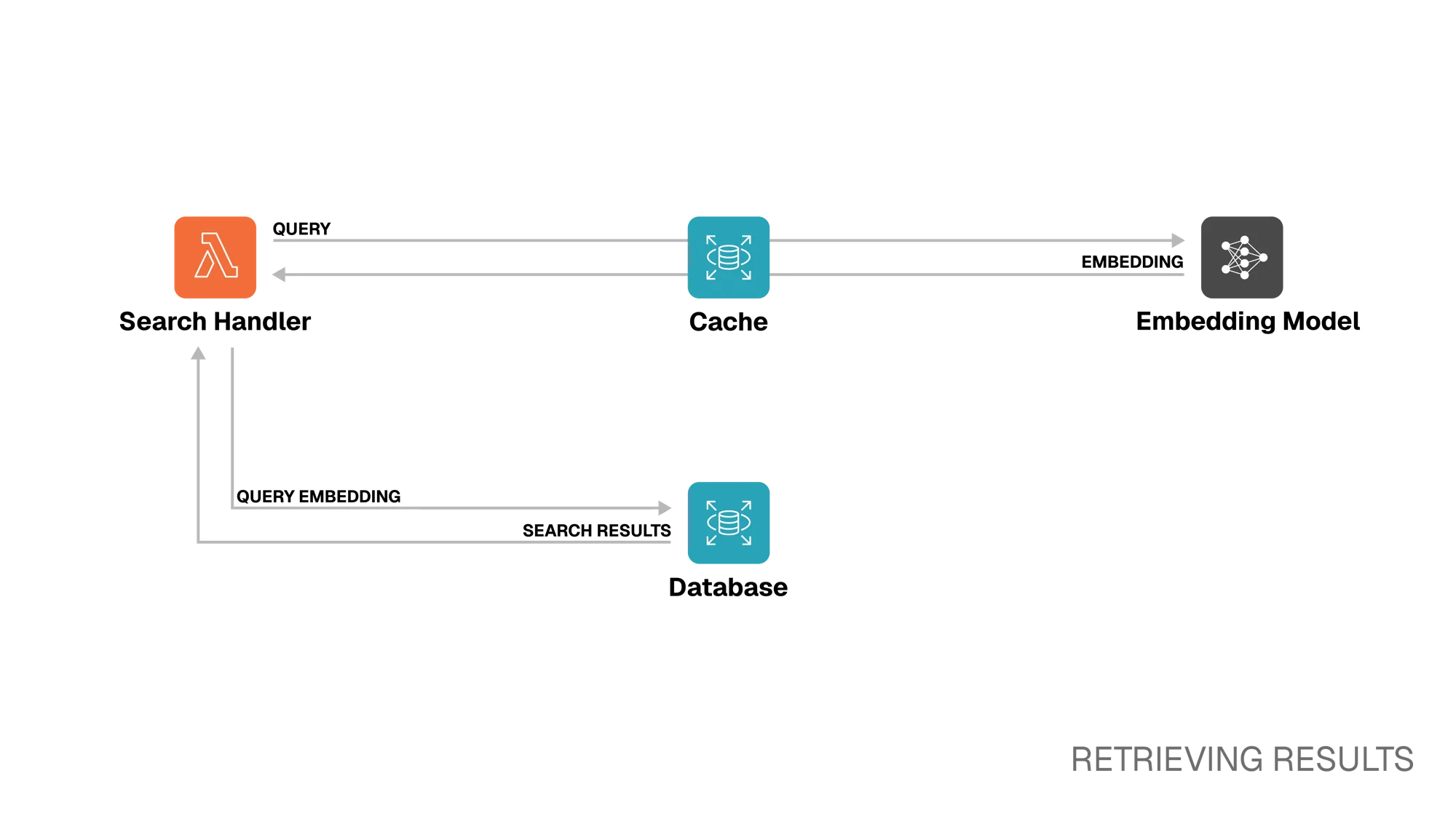
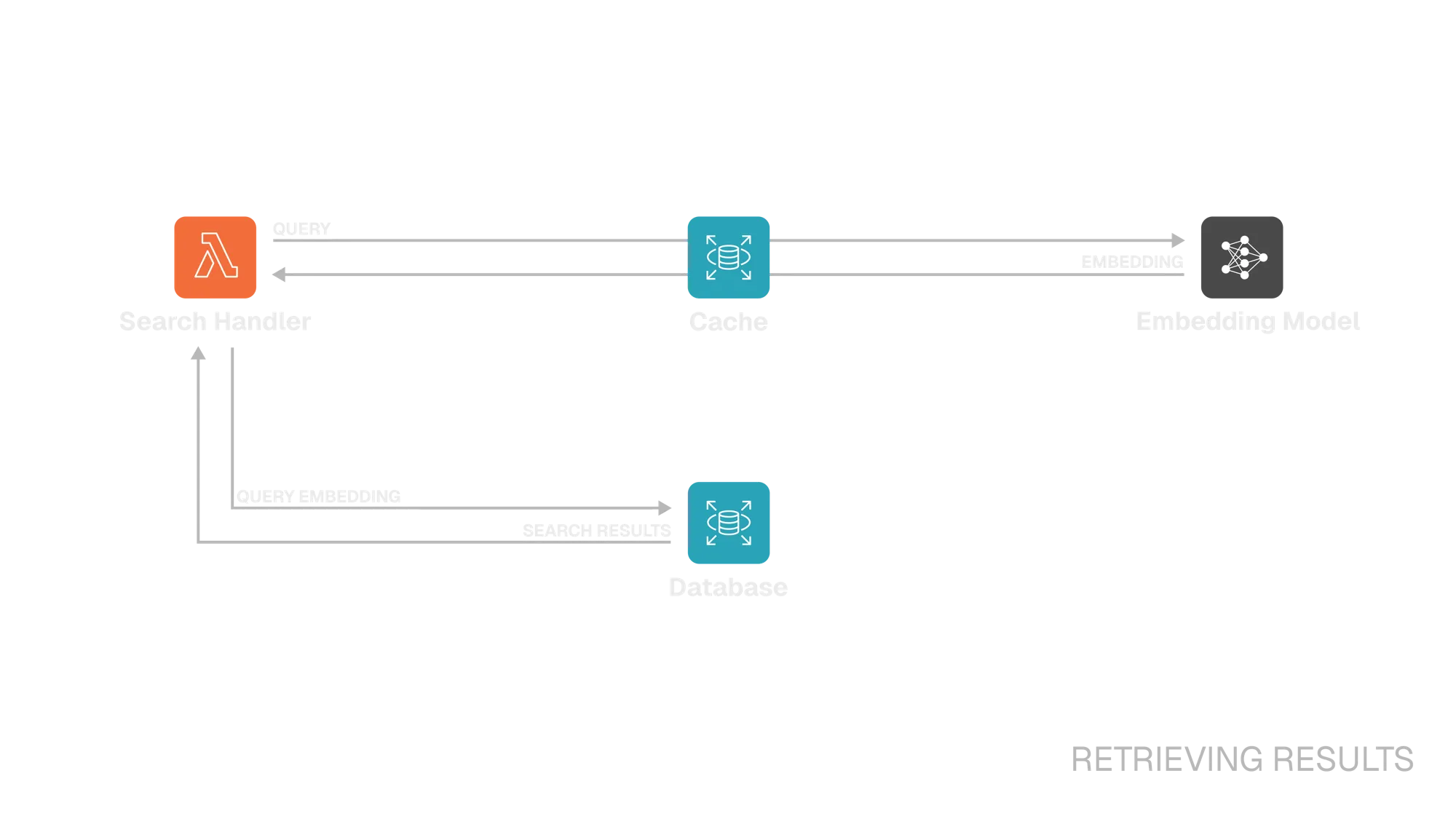
Step 3. Search Handler Lambda ⭤ Embedding Model/Cache
Before embedding the query, the Lambda checks the cache to avoid redundant embedding model calls. On cache hit, the embeddings are retrieved directly from the DynamoDB-backed cache. On cache miss, the Lambda sends the query to the embedding model. Unlike with video ingestion, this call is synchronous. The Lambda receives the embeddings, then stores them in DynamoDB.
Step 4. Search Handler Lambda ⭤ Database
The Lambda performs a semantic search using Approximate Nearest Neighbor (ANN) search with cosine similarity against stored embeddings in RDS. Filters such as modality and minimum similarity score are applied, and the top n results are retrieved.
For each match, a presigned URL gets generated to allow secure, temporary access to the video. These URLs, along with the corresponding metadata, are assembled into a structured JSON response and returned to the client.
Review - Full Architecture
Section titled “Review - Full Architecture”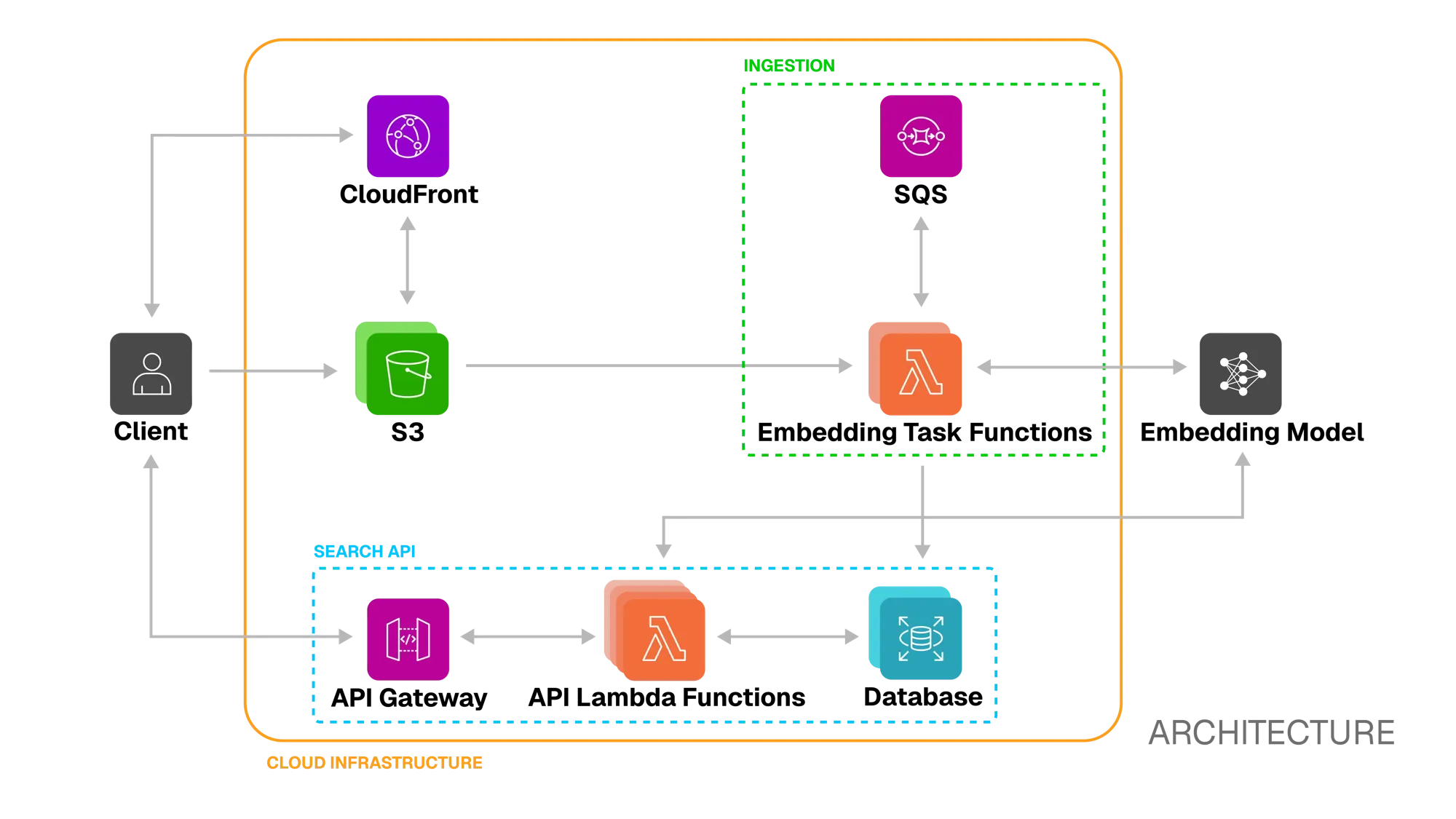
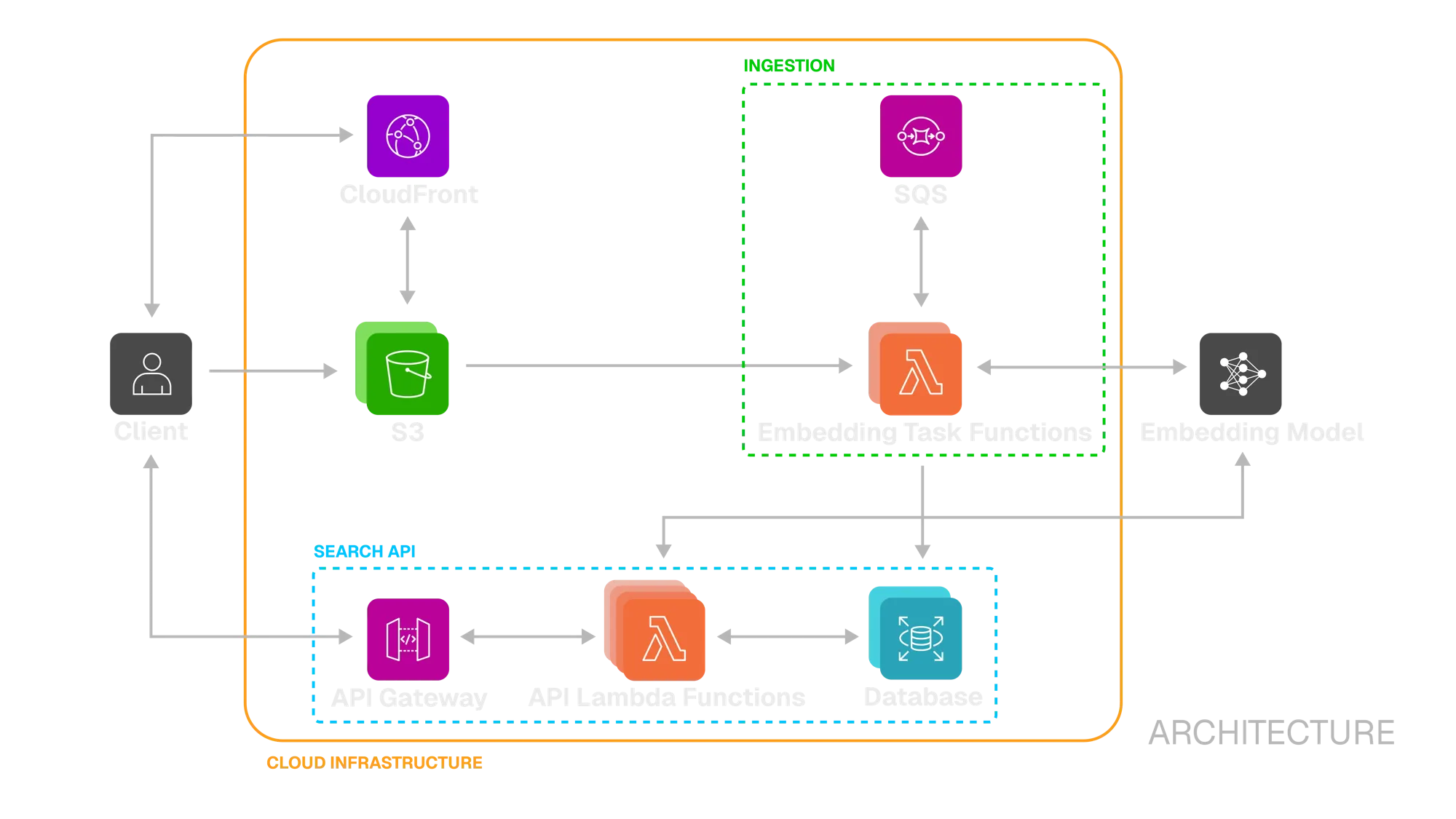
With the ingestion and search pipelines detailed above, the full architecture brings together all components into a cohesive workflow. The above diagram illustrates the end-to-end flow, showing how videos are uploaded, processed into embeddings, persisted, and later retrieved via semantic search.
Footnotes
Section titled “Footnotes”-
Limitation of Marengo 2.7 ↩