Background
The Problem with Traditional Video Search
Section titled “The Problem with Traditional Video Search”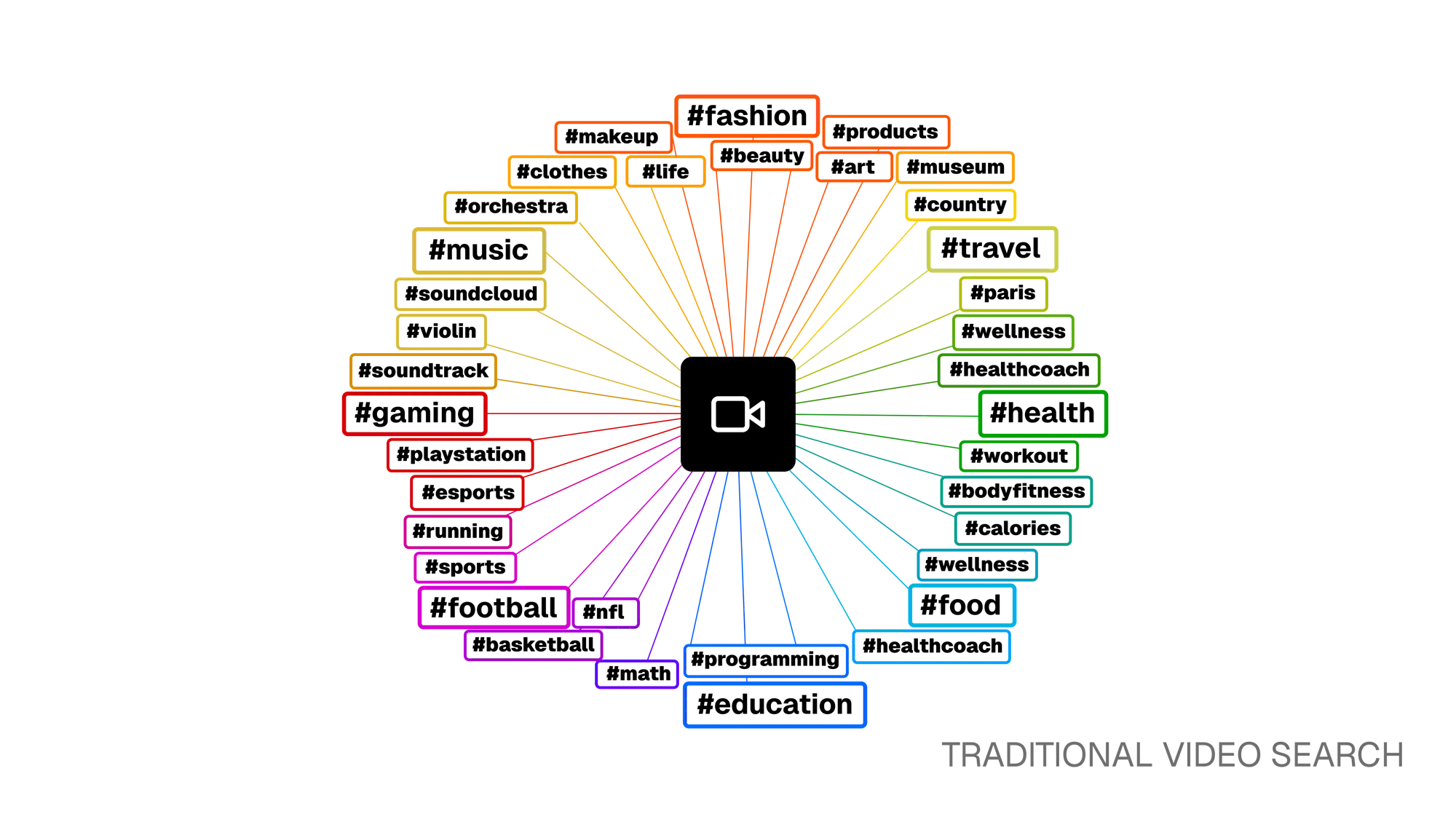
Finding specific moments inside videos has always been a challenge. Traditional search relies on exact matches on metadata like titles, tags, or short descriptions. This means the actual video content remains invisible to the search engine.
For example, the query “dog training” might miss relevant results with metadata like “canine obedience” or “puppy learning commands”. This forces users to manually scrub through hours of footage to find what they need, which is slow and frustrating.
Semantic Search
Section titled “Semantic Search”Semantic search takes a different approach. Instead of matching words letter-for-letter, it uses machine learning to understand the meaning behind a query and find content that is conceptually similar.
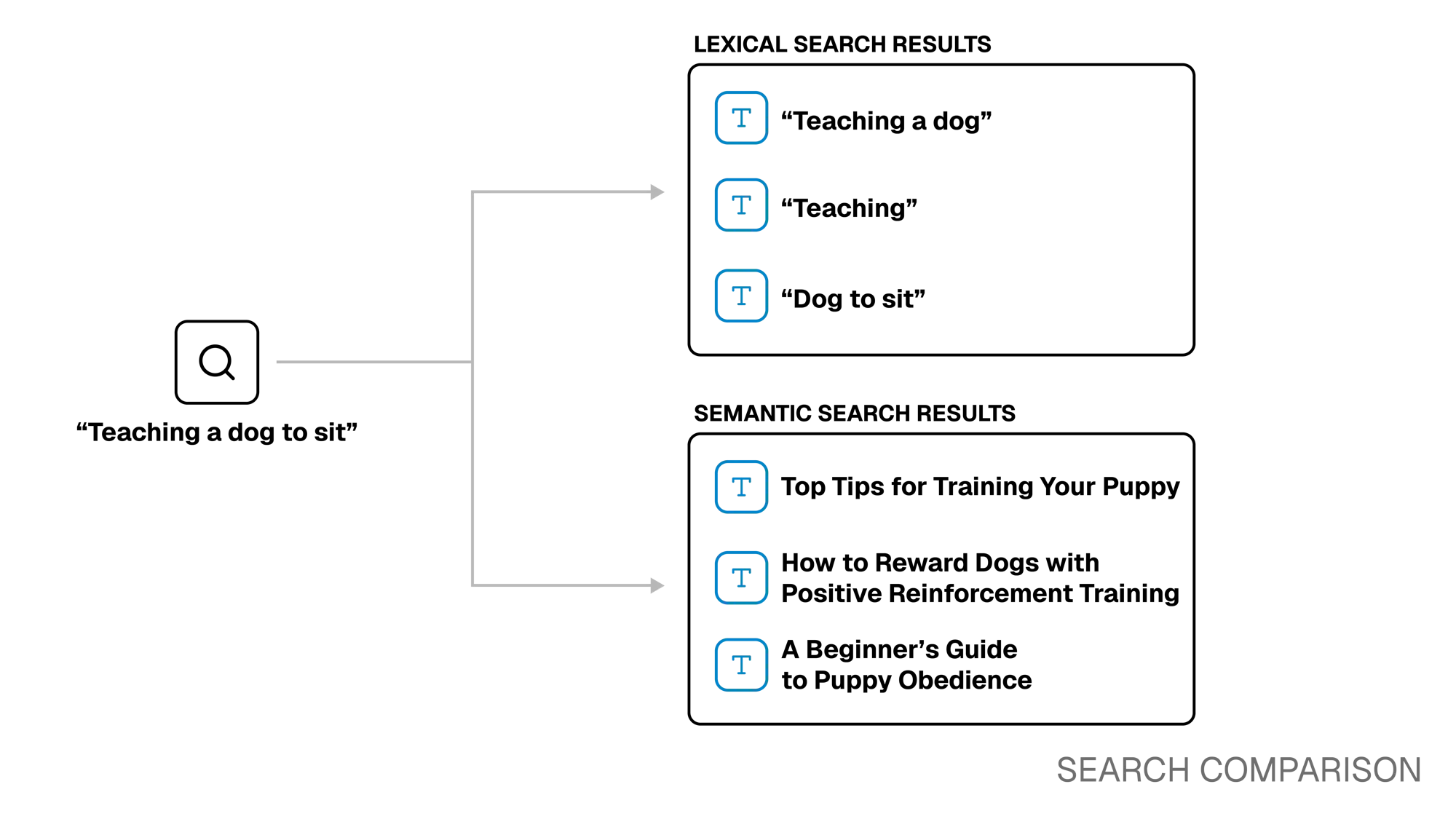
For example, if you searched for “teaching a dog to sit,” a semantic search system may find relevant content titled:
- Top Tips For Training Your Puppy.
- How to Reward Dogs With Positive Reinforcement Training.
- A Beginner’s Guide to Puppy Obedience
While these titles don’t explicitly use the terms “teaching” or “sit”, they are still retrieved because they are semantically relevant to the query.
Semantic search is more effective than keyword search because it is flexible enough to work around common pit-falls of keyword search, like differences in spelling (“color” vs. “colour”), differences in terminology (“doctor” vs. “physician”) and typos. This kind of search is enabled by a special way of encoding data called vector embeddings.
Vector Embeddings
Section titled “Vector Embeddings”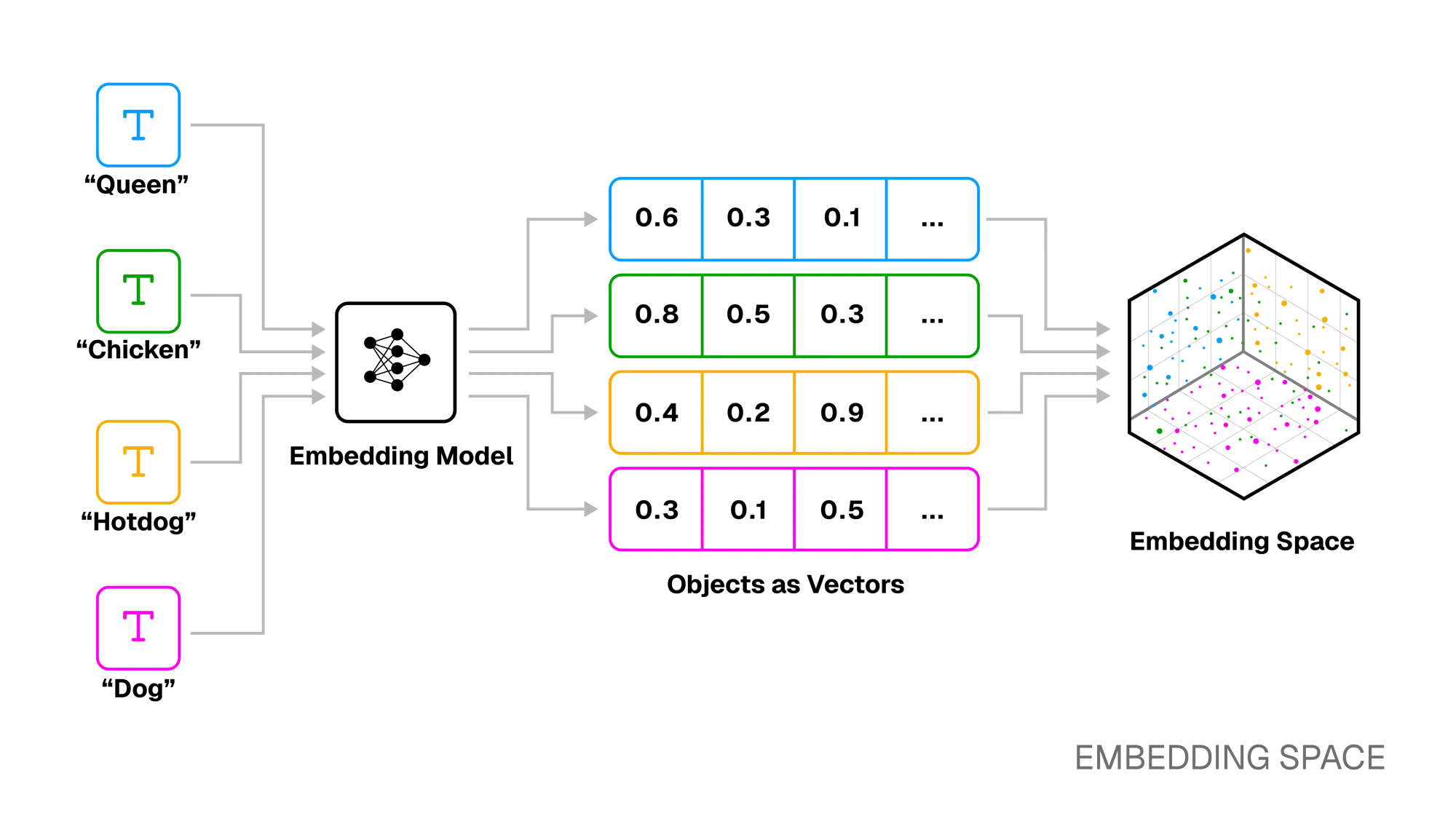
A vector embedding is a numerical representation of data within a continuous embedding space. We can think of this representation as a high-dimensional array of floating point numbers, where each dimension corresponds to a meaningful feature of that data. By converting raw, unstructured data into a structured numerical format, these vectors allow computers to process and perform mathematical operations to measure the similarity between different data points.1
Embedding models are machine learning models trained to take unstructured data and produce these vector embeddings. During training, these models learn to arrange related concepts closer to each other in the vector space, so that the resulting vectors capture the semantic meaning of the original data. This transformation, from raw data to a meaning-rich vector, is what we call embedding.
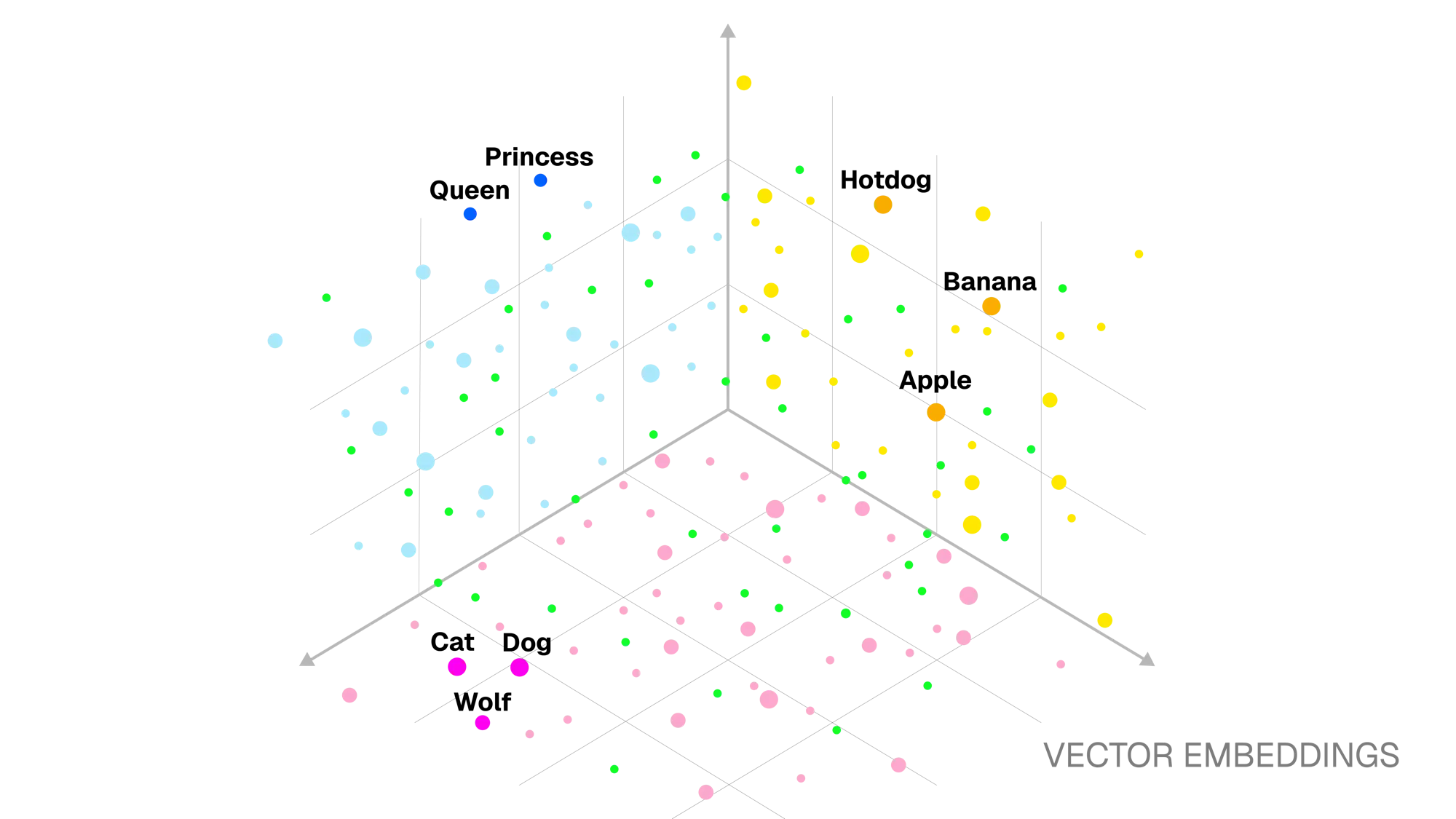
In the resulting multi-dimensional embedding space, items with similar meaning like “queen” and “princess” are placed closer together. Conversely, unrelated items like “dog” and “hotdog,” while lexically similar, are placed farther apart.
Recent Advancements in AI
Section titled “Recent Advancements in AI”Over the last few years, large language models (LLMs) like OpenAI’s GPT or Anthropic’s Claude have opened the door to a new class of intelligent applications, from autonomous agents to context-aware copilots and conversational interfaces.
App developers are increasingly building AI agents and applications that rely on LLMs to perform tasks, make decisions, and interface with other systems. These systems can be highly capable, but LLMs also come with their own set of trade-offs that product teams must design around.
A common challenge is the fact that LLMs are trained on static snapshots of internet-scale data. This means they lack up-to-date or domain-specific knowledge, especially critical in enterprise settings where internal documents, proprietary systems, or real-time events are essential to effective decision-making.2
What is RAG?
Section titled “What is RAG?”Recently, Retrieval-Augmented Generation (RAG) has grown popular as a solution to this problem. RAG works by injecting contextually relevant information into user prompts before they are sent to the LLM. This allows the LLM to generate more accurate, up-to-date, and domain-specific responses, as well as avoid hallucination.
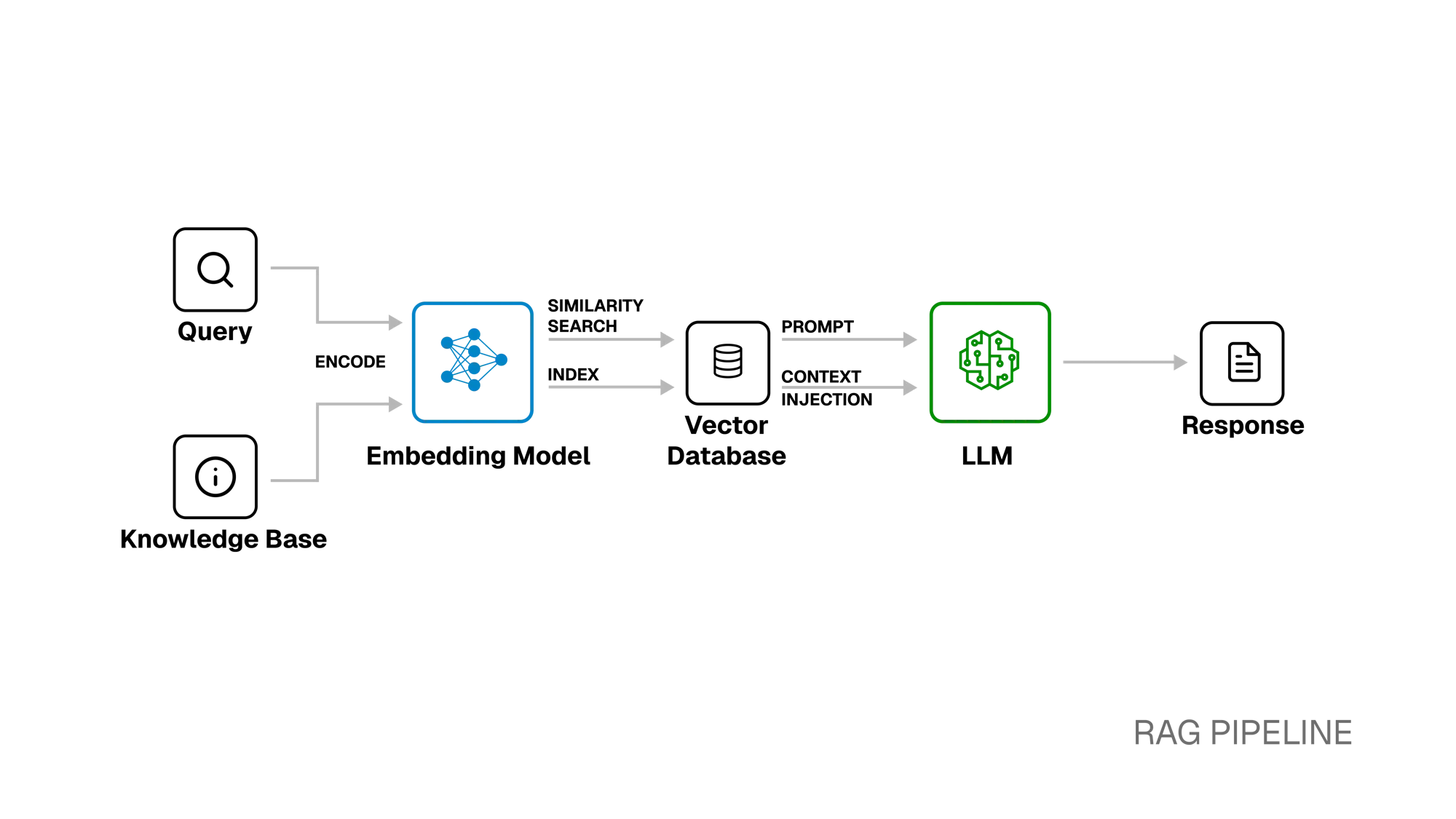
A typical RAG workflow has three core stages:
-
Knowledge Base: Source material (e.g., documents, transcripts, images, or videos) is chunked and transformed into vector embeddings using an embedding model.
-
Similarity Search: At query time, the user’s prompt is embedded into the same vector space. A vector search finds the stored embeddings most semantically similar to the query and retrieves the relevant chunks.
-
Context Injection: The retrieved chunks of source material are injected into the user’s prompt, giving the LLM targeted, context-rich information to reason with before generating its response.
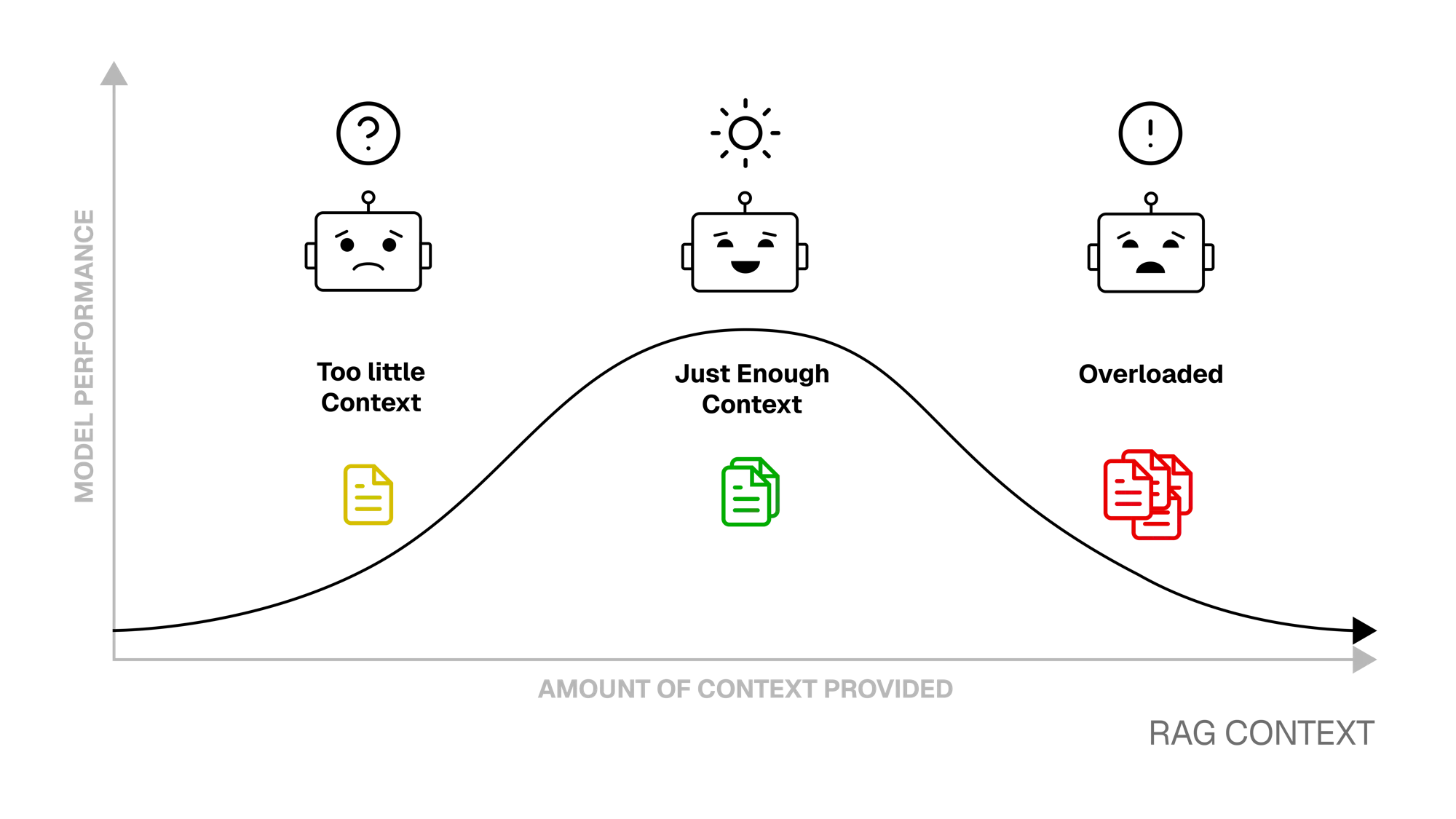
The main challenge with RAG is retrieving the most relevant context from the knowledge base. Providing too much context can overload the model and run up costs, while providing too little can cause it to hallucinate. RAG pipelines utilizing powerful embedding models and accurate search systems can strike an optimal balance by injecting only the most relevant chunks of information.
As LLM capabilities begin to extend beyond natural language processing to include formats such as image, audio, and video, an opportunity to provide different modalities of data as context to AI prompts has arisen. However, in order for RAG applications to be able to search and retrieve different types of data for context injection, they need to make use of more versatile multimodal embeddings to draw similarities between different forms of data.
Multimodal Embeddings
Section titled “Multimodal Embeddings”A modality is just a type of data - text, image, audio, or video. Traditional “unimodal” embedding models specialize in a single modality: language models for text, vision models for images, speech models for audio. Multimodal models break this barrier by learning to represent and relate features from multiple modalities within a shared embedding space.
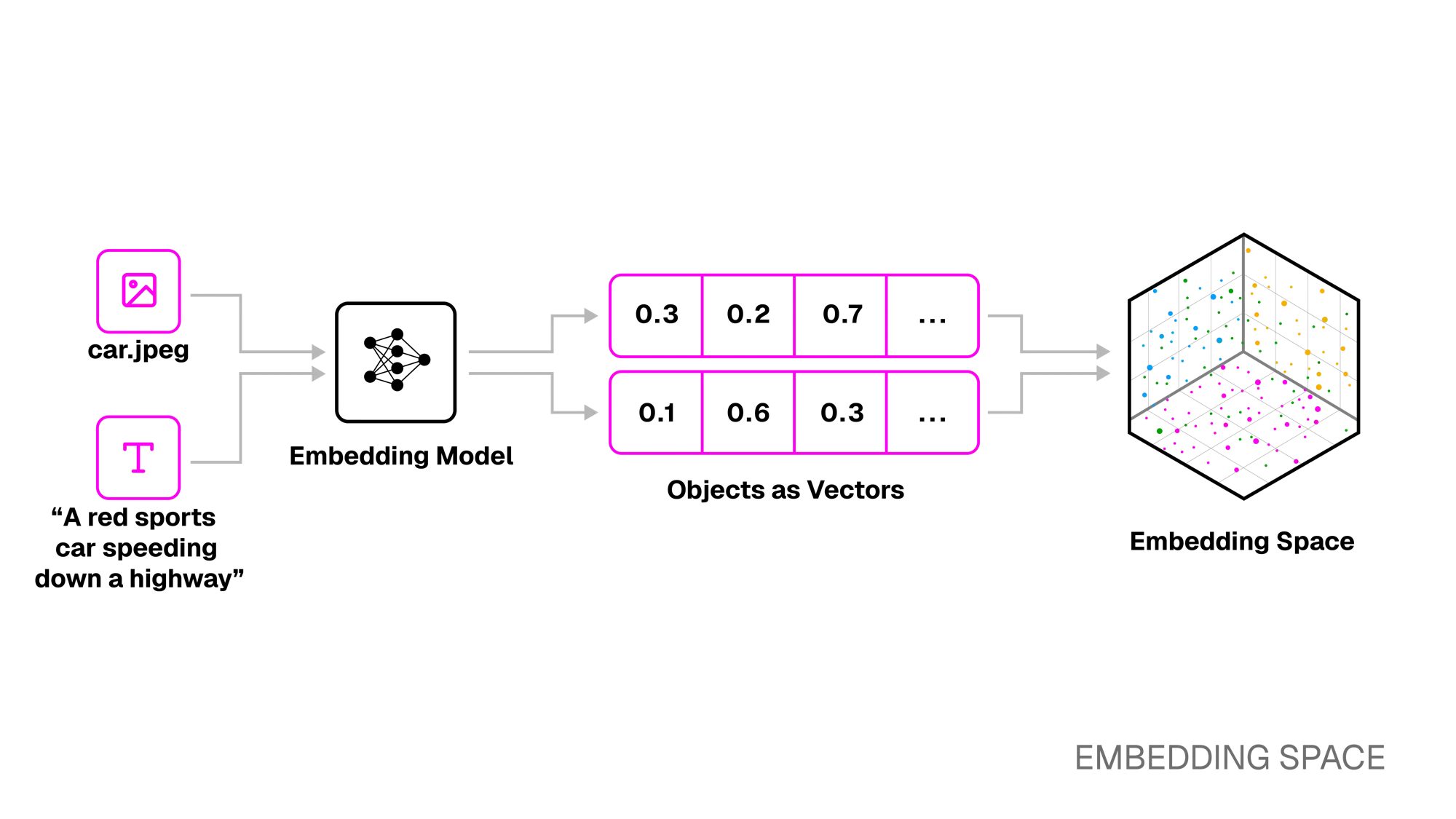
This shared embedding space allows information from different sources to be directly compared. For example, the sentence “a red sports car speeding down a highway” and an image of that same car map to nearby points in the embedding space, even though the embeddings originate from different types of data.
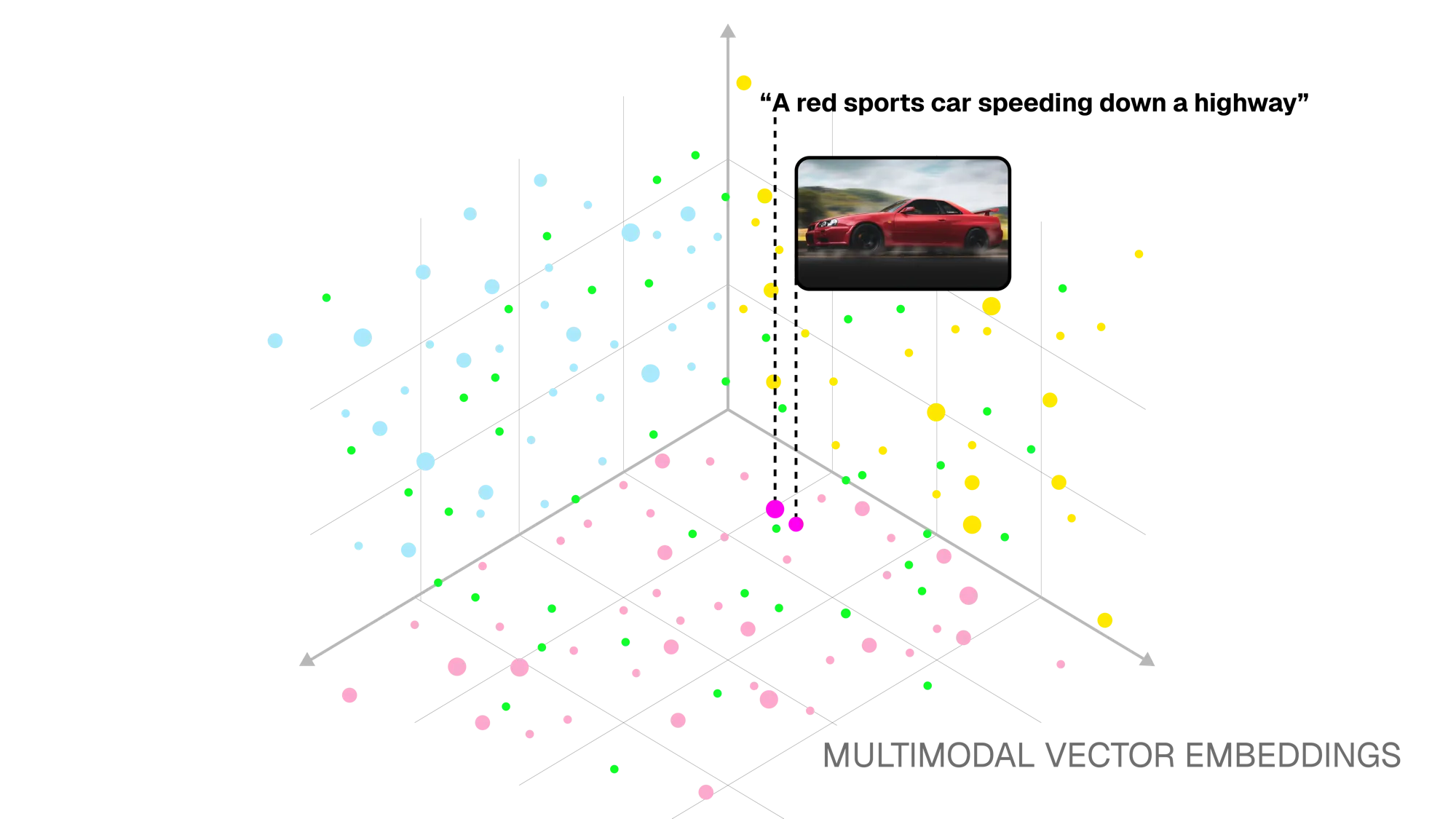
Multimodal embeddings are particularly important for video, because videos are inherently composite, combining visuals, audio, speech, and the dimension of time. They enable us to build semantic search systems that produce higher quality results, since the embedding models can combine features from multiple channels to better “understand” the content. These systems can also accept more flexible queries across modalities, allowing users to search for relevant media using text descriptions, spoken phrases, or images.
Multimodal semantic search systems are used for:
-
Creative discovery: Filmmakers can locate shots with a specific mood, composition, or sound.
-
Content management: Archivists can organize large collections by meaning, not just tags.
-
Accessibility: People can search in whichever format they’re most comfortable with, whether spoken, written, or visual.
-
Security & compliance: Security professionals can detect sensitive scenes or sounds even when they’re unlabeled.